
The Idea
Throughout history the bottleneck of image or movie capturing devices has been the film; in recent times the image
sensor. As the sensitivity of the film or image sensor was comparably low, this bottleneck enforced constraints on
the optical system and the capturing process. For low light conditions long exposure times or large lenses had to be
chosen; the first resulting in motion blur of moving objects and the second limiting the depth of field. These artefacts
have coined movie productions throughout the last century; they even became desired artistic elements and stylistic
devices in movie productions.
 During the last years new chip technologies have enhanced available image sensor to a level where this physical
bottleneck is removed. The amount of light necessary to create an image does usually not dictate camera parameters
any more. Nevertheless, motion blurs and limited depth of field are still applied for artistic means.
During the last years new chip technologies have enhanced available image sensor to a level where this physical
bottleneck is removed. The amount of light necessary to create an image does usually not dictate camera parameters
any more. Nevertheless, motion blurs and limited depth of field are still applied for artistic means.
Computational Photography alters image content by computational means to create visually appealing and artistically interesting results. Successful implementation of ideas from computational photography requires high quality data and information on the scene content. The same holds for computational videography, which transfers the ideas of computational photography to motion pictures.
Data distortion introduced for artistic means as described above limit the application of computational videography and therefore limit the artistic freedom in post processing steps. changes
the way data is acquired by striving to capture as much undisturbed information as possible by maintaining artistic
freedom and directors decisions. Thus enables the full spectrum of
computational videography without limiting neither director nor camera man in his creative freedom.
changes
the way data is acquired by striving to capture as much undisturbed information as possible by maintaining artistic
freedom and directors decisions. Thus enables the full spectrum of
computational videography without limiting neither director nor camera man in his creative freedom.
The Scene Representation Architecture (SRA) is a key innovation to enable this paradigm change described above. Major achievements are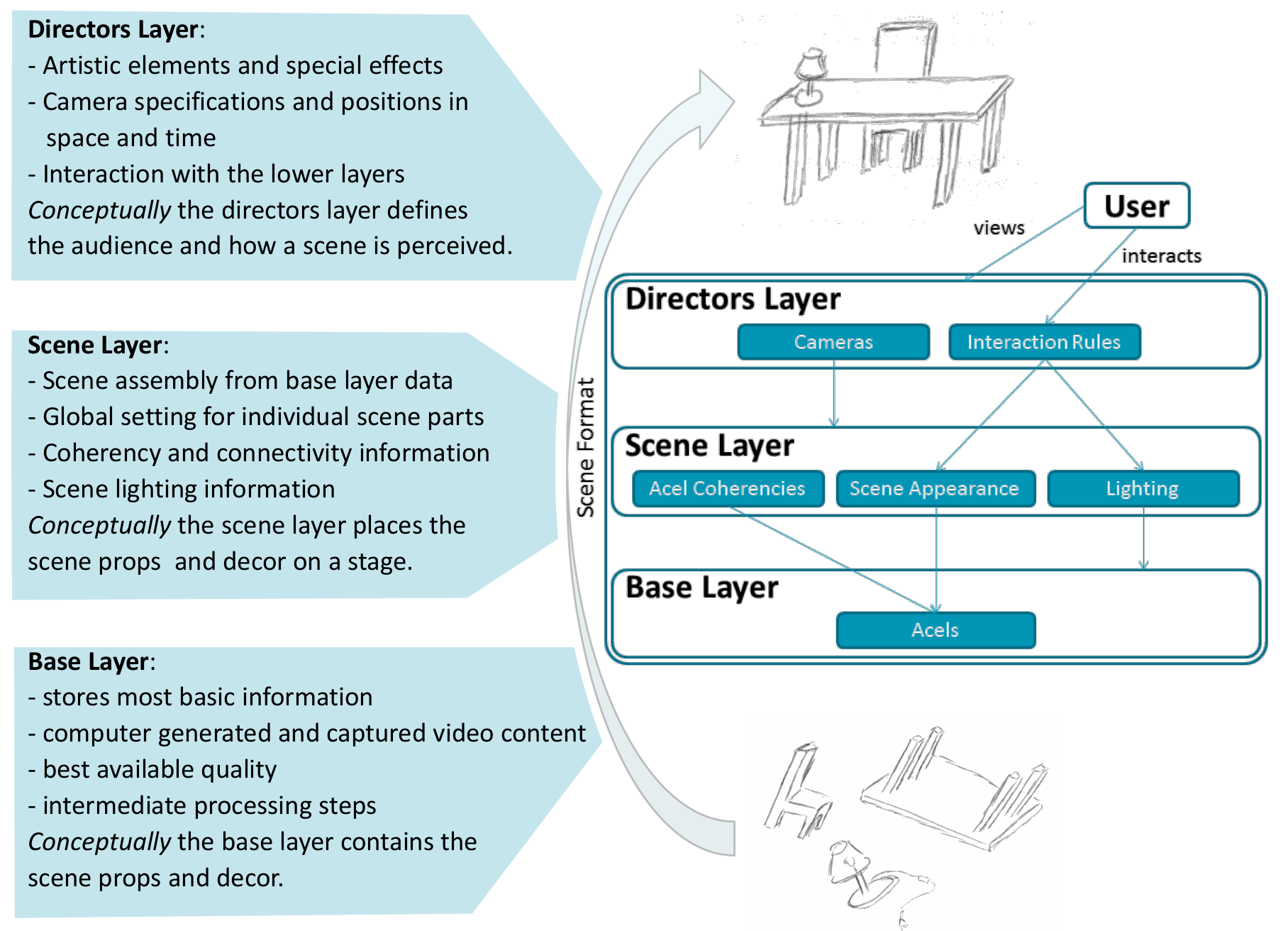
During the last years new chip technologies have enhanced available image sensor to a level where this physical
bottleneck is removed. The amount of light necessary to create an image does usually not dictate camera parameters
any more. Nevertheless, motion blurs and limited depth of field are still applied for artistic means.
Computational Photography alters image content by computational means to create visually appealing and artistically interesting results. Successful implementation of ideas from computational photography requires high quality data and information on the scene content. The same holds for computational videography, which transfers the ideas of computational photography to motion pictures.
Data distortion introduced for artistic means as described above limit the application of computational videography and therefore limit the artistic freedom in post processing steps.
changes
the way data is acquired by striving to capture as much undisturbed information as possible by maintaining artistic
freedom and directors decisions. Thus enables the full spectrum of
computational videography without limiting neither director nor camera man in his creative freedom.
The Scene Representation Architecture (SRA) is a key innovation to enable this paradigm change described above. Major achievements are
- Singe Format: When processing multidimensional video data on a computer a multitude of information sources are required: Video from several sources, camera calibration data, lighting information and spatial knowledge are just naming a few. Our proposed architecture unites all this information necessary for movie production in a single format.
- Undistorted data: When introducing artistic elements like motion blurs, depth of field or colour offsets these effects traditionally modify the captured data. Post-processing such data is time consuming and difficult. The scene representation stores all data in the best available quality and introduces altering effects in a higher layer, thus preserving all available data for facilitated image and video processing steps.
- Content Interaction: Image or video content is usually frame based. The scene representation is object based and therefore allows segmented content. Knowledge about objects in a scene allows interaction such as updated product placement, object modification or camera interaction.
- Unified Representation: Computer generated content and captured video stem from two very different worlds and are processed largely independent in movie productions. The scene representation allows a unified representation of both, computer generated and captured video data as well as any intermediate processing steps, thus merging both worlds in an early stage and facilitating post production.